
Read About my Data & Software Projects

An implementation of the Skills Space Method which uses a series of matrix operations to significantly increase runtime performance compared to a naive, list processing based approach.
(Dawson, Williams & Rizoiu 2021) provide the mathematical foundation for computing the Skill Set Similarity between two sets. However, practically implementing the functions and computations is not documented. A naive approach, that mimics the exact mathematical outline (e.g. using for loops to sum, lazy functions) is not feasible on large datasets due to poor execution performance.
As such, this report outlines and explains a method for implementing the Skills Space Method using matrix operations. The vectorisation of this method enables faster execution through SIMD or parallel computing (depending on the platform) and memoisation of necessary, static values in matrix form.
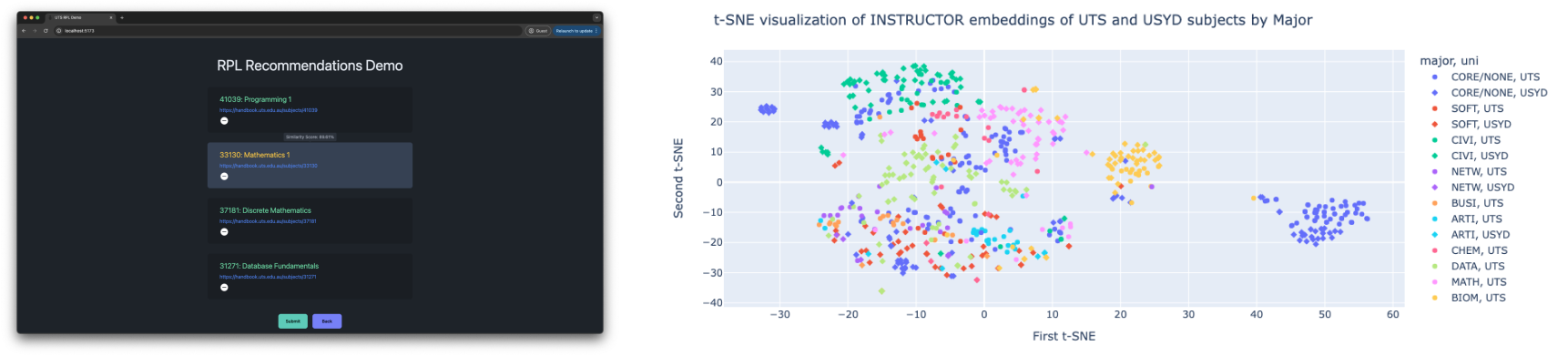
This research project delves into the efficient application of Sentence Transformers to streamline the process of Recognition of Prior Learning (RPL). RPL, an essential practice that acknowledges the skills and knowledge gained from different institutions or work experience, often necessitates extensive review and mapping of a learner's past experiences to new learning opportunities. The goal of this project is to automate and refine this manual process by deploying subject document embeddings instead of Named Entity Recognition of skills as shown in previous research.
A novel RPL-NA (Not Applicable) classification model is developed, which helps discern whether a subject is definitely not applicable for RPL for another subject, acting as an automated filter for similarity search. The project details the creation of a new dataset via web scraping, the selection and effectiveness of specific Transformer models, and the integration of these models in a Decision Support System (DSS) application. It also provides insight into the challenges faced during implementation and discusses the results derived from various testing methodologies.
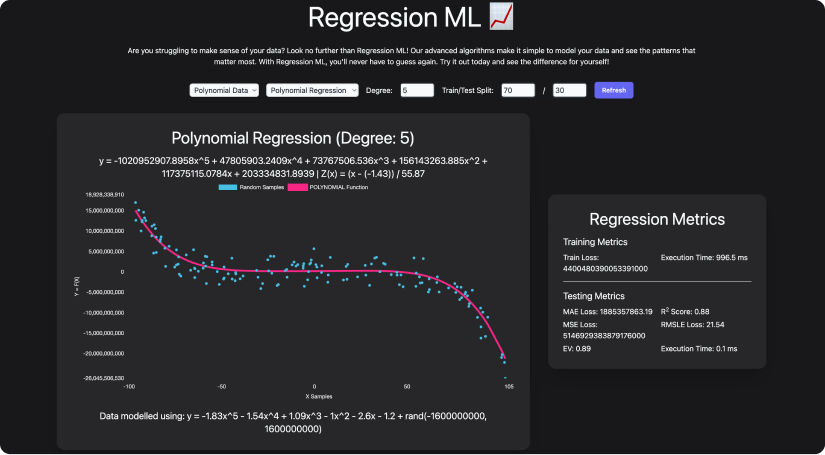
About Regression App is an application which visualises Linear, Polynomial and Decision Tree Regression using algorithms I wrote from scratch in Typescript. It also enables you to provide your own data instead of using random generation.
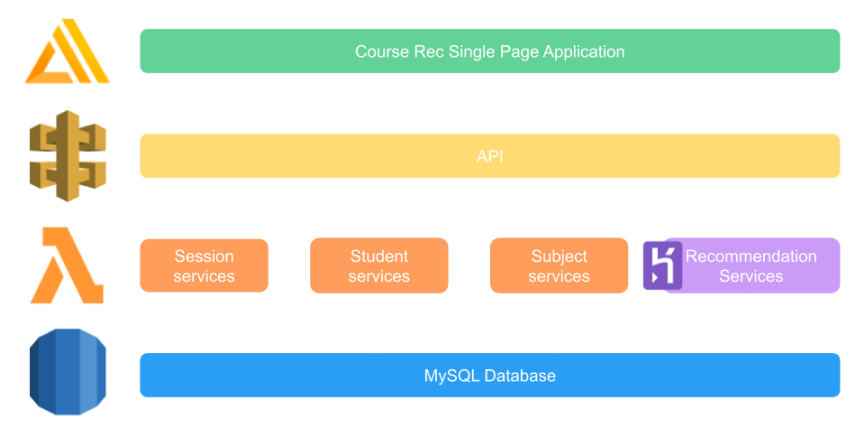
Developed using Node.js and Python, and hosted on AWS services including Amplify, API Gateway, Lambda, RDS and EC2. Course commendation backend is a full stack web application that uses data scraped from the UTS handbook to recommend subjects using a KNN model that uses data from the past subjects a student has taken and a personality quiz.
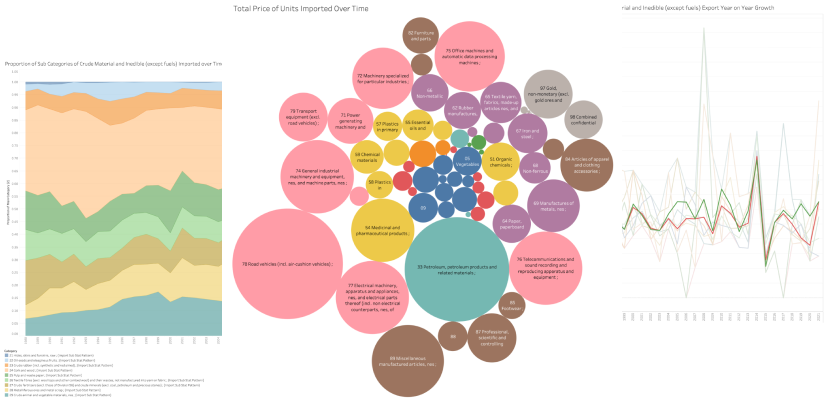
This project involved a comprehensive analysis and visualization of Australian international trade data, showcasing a range of data science techniques and tools. The work began with exploratory data analysis using Python libraries such as Pandas, NumPy, and Seaborn to uncover patterns and correlations within the trade data. This was followed by meticulous data cleaning and preprocessing to handle missing values, convert data types, and prepare the dataset for visualization. The heart of the project lay in creating interactive visualizations using Tableau, including time series charts, stacked area charts, and bubble charts, all designed to illustrate import and export trends across various product categories.


